Scaling evaluation systems for agentic platforms from prototype to prod
Recently, I was listening to an interview with Boris Cherny, the creator of Claude Code, on Anthropic's YouTube channel. When asked about the evaluation set for Claude Code, his response got me thinking: "We just run on vibes."
It was a glib response, but as he elaborated, it revealed something about their development process. They have an incredibly tight feedback loop—they make changes, ship them immediately to everyone at Anthropic who's dogfooding the application, and get feedback within hours if not minutes. His team members ARE the test harness.
Most of us don't have this luxury. We have longer feedback cycles, external users with different needs, and require systematic testing process for confidence. The question becomes: when do you rely on vibes, and when do you need a rigorous validation process?
The Reality Check: Models Are Just One Part of the System
When people talk about evaluations, they are typically referring to the process of evaluating an LLM’s capabilities. There are many evaluation sets used to test different aspects of an LLM’s ability, what’s interesting to software engineers is evaluation sets like the SWE-bench.
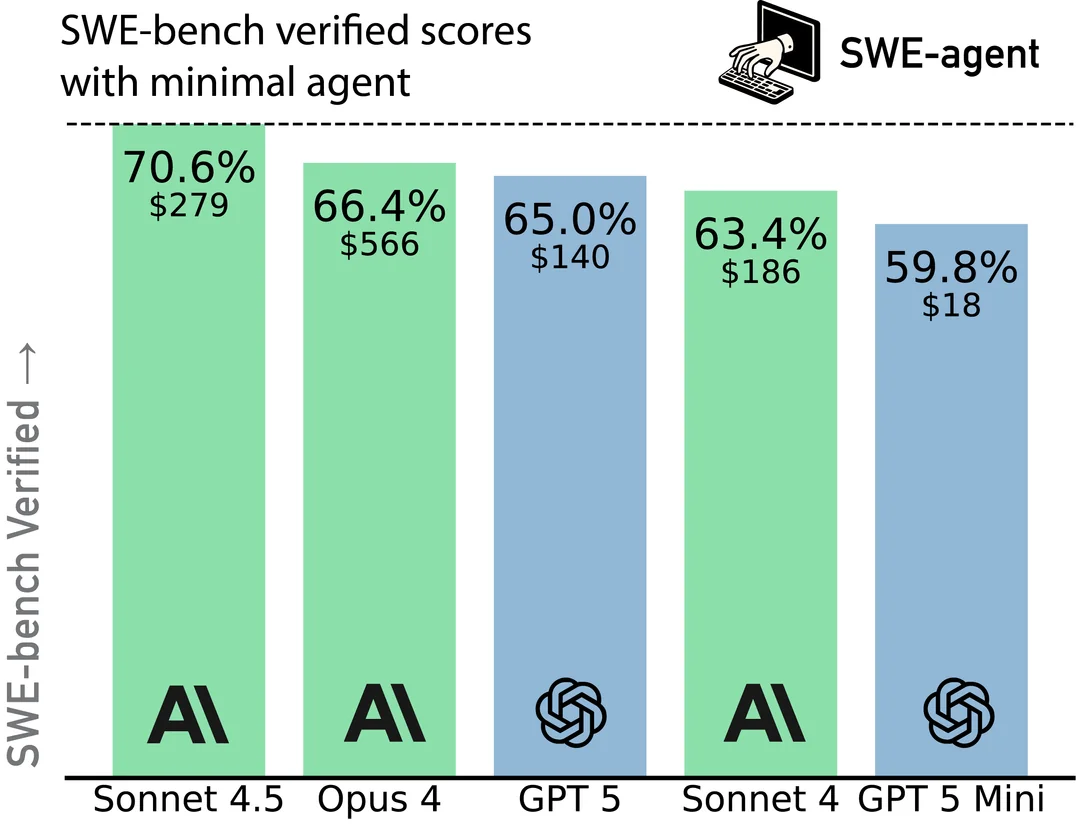
The SWE-bench evaluation is a leaderboard of the top-performing LLMs in terms of a software engineering challenge. It consists of over 2000 GitHub issues with code and a failing unit test. Sonnet 3.5 solves 70% of these issues for $279 in token costs, while GPT-4 solves nearly 60% for just $18, [1]. These trade-offs between precision and cost are exactly what we need to uncover in our own systems.
Before diving into evaluation strategies, let's clarify what we're actually testing. It is one thing to test an LLMs response to a question when the answer is embedded in the LLM's memory, but when we talk about agentic systems, we're dealing with orchestrated autonomous systems that integrate both agents and workflows to pursue multiple goals, manage complex task execution, and adapt their behaviour in response to dynamic context and feedback. At its heart, you have the LLM doing orchestration, but it's using tools in a loop—sending requests to external APIs, executing bash commands, feeding these responses back to the LLM, and continuing until the task is complete. We package this into agents with system prompts, tools, memory, and security controls. These run in environments (command line, Docker containers, chat interfaces) on platforms that expose knowledge bases, MCP meshes, sandbox architectures, and telemetry.
How do we test all of these components especially when the system under test is the decision the LLM makes?
My Journey from Prototype to Production
To illustrate these concepts, I will share my experience with a simple agent I built, i-am-committed. It is a command-line application that produces conventional commit messages from git diffs. What started as an experiment in vibe coding has became a useful utility and an interesting thought experiment.
It's truly an agent because I've given the LLM tools and asked it to orchestrate them. It has the freedom to call git in multiple ways—not just diff, but examining logs and history to compose the correct commit message. A git commit message costs less than a cent, but keeping an eye on costs and understanding token usage became an important part of the experiment.
As I built this, recursive questions emerged:
- Am I using the right model? ChatGPT vs Gemini vs Claude?
- Could I be using a cheaper model?
- How many times does the agent iterate?
- Why does it sometimes hallucinate?
- Could my agent do something rogue? It has access to git—could it delete code?
- Are the commit messages even good?
With the pace of change in the industry, these questions multiply. Every model release creates new questions. Every agent added to a multi-agent system creates more complexity. Every feature needs more testing.
The Eval Pyramid: From Unit Tests to Production
For our agentic systems we need to have a Validation System that incorporates traditional testing of our deterministic components and an evaluation approach for our none deterministic components.
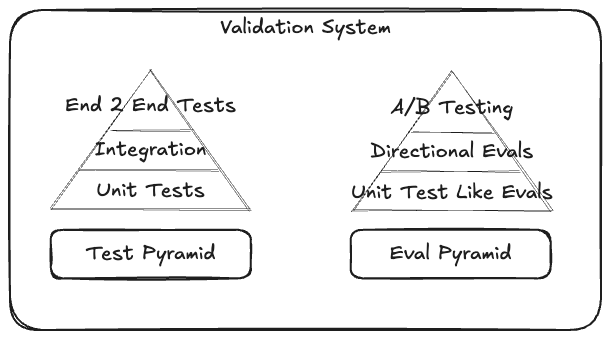
The traditional software testing pyramid starts with unit tests at the bottom, integration tests in the middle, and end-to-end tests at the top. The eval pyramid looks similar but is subtly different:
Level 1: Unit Test Evals
These are quick, predictable, and cheap to run. They test basic functionality and run as part of your CI pipeline. In my commit message agent, I test whether the output adheres to conventional commit structure using regex. It's fast, cheap, and catches basic failures. I have a golden dataset built from commit messages and git diffs captured in my log files. There are 100 records, fast to execute cheap(ish) to run. I can now reliably play with my system prompt or even swap out my LLM model for another, knowing I wont break my application.
Building golden datasets for these types of tests can be challenging. Hugging Face has a large dataset of git commit messages scraped from public GitHub repos—over a million rows. But be careful: running tests against that entire dataset would cost over $1,000.
Your golden dataset should be curated to test the boundaries of your application, in my example these are corrupt diffs, tiny irrelevant changes, large complex changes etc.
Level 2: Directional Evals
These ensure your system doesn't drift and quality doesn't degrade over time. They're more complex and expensive to run. I use the concept of LLM as a judge—taking the response from my agent and feeding it to another LLM to evaluate quality of the commit message against the set objectives.
This doubles your token costs and adds another system to tune. These tests aren't for every commit—they're for major changes, version bumps, weekly builds, or when switching models or tuning system prompts.
The directional Evals use the same golden dataset, but evaluate "quality" and "taste". You may even use a different LLM as the judge to ensure you are testing the problem space from different perspectives.
Level 3: Testing in Live
To understand how your system really works, you need instrumentation. OpenTelemetry with conventions like OpenInference lets you trace the full flow: session starts, agent calls, LLM completions, tool calls, final results. You can capture system prompts, models used, latency, timings, and even calculate costs.
Tools like Phoenix (which I use) or LangSmith allow you to flag good and bad results, capture that data, and bring it back into your evaluation sets. This creates a virtuous cycle of improvement.
Capturing Signal from Humans in the Loop
If you're not Boris Cherny with his instant feedback loop, you need to design your agents to expose a signal for good or bad outcomes:
Explicit signals: Thumbs up/down ratings (like ChatGPT)
Implicit signals: In my git commit agent:
- User approves message = positive signal
- User edits = neutral signal
- User cancels = negative signal
For autonomous agents running headless, you might need "LLM in the loop" approaches, using LLMs to derive positive signals from agent behaviour.
Validation System
As the picture starts to evolve its easy to see that our agentic system is actually composed of an agent and a validation system, which in turn is composed of a traditional deterministic testing framework, along with a complex hierarchy of evaluation tests and an observability system that gives you x-ray vision into the usage and behaviour of your application.
The Path Forward: Building Your Validation Strategy
Here's my call to action for teams building agentic systems:
-
Build observability primitives into your platform: Make telemetry a core component, not an afterthought.
-
Capture your golden dataset: Focus on diversity of use cases. With GenAI coding tools, parsing logs and building datasets is easier than ever (Claude Code is your friend).
-
Build your directional eval suite: Treat your LLM-as-judge as a first-class component of your application, not just a testing framework.
-
Don't be afraid to create your own tooling: It's too early to couple yourself to third-party solutions. Things are evolving too quickly.
-
Test in live: Capture signals, use telemetry to find poor performance, update your golden datasets with failures.
-
Look for opportunities to use cheaper, task-focused models: Nvidia's recent white paper suggests [small language models are the future of agentic systems(https://arxiv.org/abs/2506.02153).
Embracing the Complexity
As we build these platforms, the diversity of tasks will grow. Having a diverse set of small models, honed and evaluated for specific scenarios, then coordinated within your platform, will become increasingly important. And as that complexity explodes, your telemetry system becomes even more critical.
The journey from vibes to validation isn't about abandoning intuition—it's about supplementing it with systematic approaches that scale. Boris Cherny can run on vibes because he has a perfect feedback loop. The rest of us need to build our own loops, one evaluation at a time.
Remember: the code for my experiments is available on my GitHub. I encourage you to build these little agents and systems. Only through building do you start to understand the problems and challenges, and then figure out how to industrialise them for production environments.
RAG Systems
An interesting question was raised about the usage of LLM-as-a-judge for testing Resource Augmented Retrieval (RAG) systems. RAG systems pose a challenge as you are evaluating that the LLM has retrieved the information and interpreted it correctly. This is not something that can be tested deterministically, but rather an LLM can be used to test at scale.
RAG Evaluation Systems rely on the concept of the RAG Triad.
- Context Relevance: The retrieved documents align to the systems/users query
- Groundedness: generated response is based accurately on the retrieved context
- Answer Relevance: how well the final response addresses the systems/user's original query
Building an LLM-as-a-judge evaluation system that tests against the dimensions of the RAG Triad gives a more structured evaluation approach than a basic test of "quality" or "relevance".
Footnote
Links
- https://github.com/darkin100/i-am-committed/
- https://www.youtube.com/watch?v=qTI9Se97Lpk
- https://blog.glyndarkin.co.uk/
As of 19th November 2026 ↩︎